Методы временных рядов. Реферат: Временные ряды
АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
ВВЕДЕНИЕ
ГЛАВА 1. АНАЛИЗ ВРЕМЕННЫХ РЯДОВ
1.1 ВРЕМЕННОЙ РЯД И ЕГО ОСНОВНЫЕ ЭЛЕМЕНТЫ
1.2 АВТОКОРРЕЛЯЦИЯ УРОВНЕЙ ВРЕМЕННОГО РЯДА И ВЫЯВЛЕНИЕ ЕГО СТРУКТУРЫ
1.3 МОДЕЛИРОВАНИЕ ТЕНДЕНЦИИ ВРЕМЕННОГО РЯДА
1.4 МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
1.5 ПРИВЕДЕНИЕ УРАВНЕНИЯ ТРЕНДА К ЛИНЕЙНОМУ ВИДУ
1.6 ОЦЕНКА ПАРАМЕТРОВ УРАВНЕНИЯ РЕГРЕССИИ
1.7 АДДИТИВНАЯ И МУЛЬТИПЛИКАТИВНАЯ МОДЕЛИ ВРЕМЕННОГО РЯДА
1.8 СТАЦИОНАРНЫЕ ВРЕМЕННЫЕ РЯДЫ
1.9 ПРИМЕНЕНИЕ БЫСТРОГО ПРЕОБРАЗОВАНИЯ ФУРЬЕ К СТАЦИОНАРНОМУ ВРЕМЕННОМУ РЯДУ
1.10 АВТОКОРРЕЛЯЦИЯ ОСТАТКОВ. КРИТЕРИЙ ДАРБИНА- УОТСОНА
Введение
Почти в каждой области встречаются явления, которые интересно и важно изучать в их развитии и изменении во времени. В повседневной жизни могут представлять интерес, например, метеорологические условия, цены на тот или иной товар, те или иные характеристики состояния здоровья индивидуума и т. д. Все они изменяются во времени. С течением времени изменяются деловая активность, режим протекания того или иного производственного процесса, глубина сна человека, восприятие телевизионной программы. Совокупность измерений какой-либо одной характеристики подобного рода в течение некоторого периода времени представляют собой временной ряд.
Совокупность существующих методов анализа таких рядов наблюдений называется анализом временных рядов.
Основной чертой, выделяющей анализ временных рядов среди других видов статистического анализа, является существенность порядка, в котором производятся наблюдения. Если во многих задачах наблюдения статистически независимы, то во временных рядах они, как правило, зависимы, и характер этой зависимости может определяться положением наблюдений в последовательности. Природа ряда и структура порождающего ряд процесса могут предопределять порядок образования последовательности.
Цель работы состоит в получении модели для дискретного временного ряда во временной области, обладающей максимальной простотой и минимальным числом параметров и при этом адекватно описывающей наблюдения.
Получение такой модели важно по следующим причинам:
1) она может помочь понять природу системы, генерирующей временные ряды;
2) управлять процессом, порождающим ряд;
3) ее можно использовать для оптимального прогнозирования будущих значений временных рядов;
Временные ряды лучше всего описываются нестационарными моделями, в которых тренды и другие псевдоустойчивые характеристики, возможно меняющиеся во времени, рассматриваются скорее как статистические, а не детерминированные явления. Кроме того, временные ряды, связанные с экономикой, часто обладают заметными сезонными , или периодическими, компонентами; эти компоненты могут меняться во времени и должны описываться циклическими статистическими (возможно, нестационарными) моделями.
Пусть наблюдаемым временным рядом является y 1 , y 2 , . . ., y n . Мы будем понимать эту запись следующим образом. Имеется Т чисел, представляющих собой наблюдение некоторой переменной в Т равноотстоящих моментов времени. Эти моменты для удобства пронумерованы целыми числами 1, 2, . . .,Т. Достаточно общей математической (статистической или вероятностной) моделью служит модель вида:
y t = f(t) + u t , t = 1, 2, . . ., T.
В этой модели наблюдаемый ряд рассматривается как сумма некоторой полностью детерминированной последовательности {f(t)}, которую можно назвать математической составляющей, и случайной последовательности {u t }, подчиняющейся некоторому вероятностному закону. (И иногда для этих двух составляющих используются соответственно термины сигнал и шум). Эти компоненты наблюдаемого ряда ненаблюдаемы; они являются теоретическими величинами. Точный смысл указанного разложения зависит не только от самих данных, но частично и оттого, что понимается под повторением эксперимента, результатом которого являются эти данные. Здесь используется так называемая «частотная» интерпретация. Полагается, что, по крайней мере, принципиально можно повторять всю ситуацию целиком, получая новые совокупности наблюдений. Случайные составляющие, кроме всего прочего, могут включать в себя ошибки наблюдений.
В данной работе рассмотрена модель временного ряда, в которой на тренд накладывается случайная составляющая, образующая случайный стационарный процесс. В такой модели предполагается, что течение времени никак не отражается на случайной составляющей. Точнее говоря, предполагается, что математическое ожидание (то есть среднее значение) случайной составляющей тождественно равно нулю, дисперсия равна некоторой постоянной и что значения u t в различные моменты времени некоррелированны. Таким образом, всякая зависимость от времени включается в систематическую составляющую f(t). Последовательность f(t) может зависеть от некоторых неизвестных коэффициентов и от известных величин, меняющихся со временем. В этом случае её называют «функцией регрессии». Методы статистических выводов для коэффициентов функции регрессии оказываются полезными во многих областях статистики. Своеобразие же методов, относящихся именно к временным рядам, состоит в том, что здесь исследуются те модели, в которых упомянутые выше величины, меняющиеся со временем, являются известными функциями t.
Глава 1. Анализ временных рядов
1.1 Временной ряд и его основные элементы
Временной ряд –это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
· факторы, формирующие тенденцию ряда;
· факторы, формирующие циклические колебания ряда;
· случайные факторы.
При различных сочетаниях в изучаемом процессе или явлении этих факторов зависимость уровней ряда от времени может принимать различные формы. Во-первых , большинство временных рядов экономических показателей имеют тенденцию, характеризующую долговременное совокупное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что эти факторы, взятые в отдельности, могут оказывать разнонаправленное влияние на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку деятельность ряда отраслей экономики и сельского хозяйства зависит от времени года. При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой временного ряда.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень образуется как сумма среднего уровня ряда и некоторой(положительной или отрицательной) случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью временного ряда. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью временного ряда. Основная задача статистического исследования отдельного временного ряда – выявление и придание количественного выражения каждой из перечисленных выше компонент с тем чтобы использовать полученную информацию для прогнозирования будущих значений ряда.
1.2 Автокорреляция уровней временного ряда и выявление его структуры
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией уровней ряда .
Количественно её можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени.
Одна из рабочих формул для расчёта коэффициента автокорреляции имеет вид:
(1.2.1)В качестве переменной х мы рассмотрим ряд y 2 , y 3 , … , y n ; в качестве переменной у – ряд y 1 , y 2 , . . . ,y n – 1 . Тогда приведённая выше формула примет вид:
(1.2.2)Аналогично можно определить коэффициенты автокорреляции второго и более высоких порядков. Так, коэффициент автокорреляции второго порядка характеризует тесноту связи между уровнями у t и y t – 1 и определяется по формуле
(1.2.3)Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом . С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается. Некоторые авторы считают целесообразным для обеспечения статистической достоверности коэффициентов автокорреляции использовать правило – максимальный лаг должен быть не больше (n/4).
В трех предыдущих заметках описаны регрессионные модели, позволяющие прогнозировать отклик по значениям объясняющих переменных. В настоящей заметке мы покажем, как с помощью этих моделей и других статистических методов анализировать данные, собранные на протяжении последовательных временных интервалов. В соответствии с особенностями каждой компании, упомянутой в сценарии, мы рассмотрим три альтернативных подхода к анализу временных рядов.
Материал будет проиллюстрирован сквозным примером: прогнозирование доходов трех компаний . Представьте себе, что вы работаете аналитиком в крупной финансовой компании. Чтобы оценить инвестиционные перспективы своих клиентов, вам необходимо предсказать доходы трех компаний. Для этого вы собрали данные о трех интересующих вас компаниях - Eastman Kodak, Cabot Corporation и Wal-Mart. Поскольку компании различаются по виду деловой активности, каждый временной ряд обладает своими уникальными особенностями. Следовательно, для прогнозирования необходимо применять разные модели. Как выбрать наилучшую модель прогнозирования для каждой компании? Как оценить инвестиционные перспективы на основе результатов прогнозирования?
Обсуждение начинается с анализа ежегодных данных. Демонстрируются два метода сглаживания таких данных: скользящее среднее и экспоненциальное сглаживание. Затем демонстрируется процедура вычисления тренда с помощью метода наименьших квадратов и более сложные методы прогнозирования. В заключение, эти модели распространяются на временные ряды, построенные на основе ежемесячных или ежеквартальных данных.
Скачать заметку в формате или , примеры в формате
Прогнозирование в бизнесе
Поскольку экономические условия с течением времени изменяются, менеджеры должны прогнозировать влияние, которое эти изменения окажут на их компанию. Одним из методов, позволяющих обеспечить точное планирование, является прогнозирование. Несмотря на большое количество разработанных методов, все они преследуют одну и ту же цель - предсказать события, которые произойдут в будущем, чтобы учесть их при разработке планов и стратегии развития компании.
Современное общество постоянно испытывает необходимость в прогнозировании. Например, чтобы выработать правильную политику, члены правительства должны прогнозировать уровни безработицы, инфляции, промышленного производства, подоходного налога отдельных лиц и корпораций. Чтобы определить потребности в оборудовании и персонале, директора авиакомпаний должны правильно предсказать объем авиаперевозок. Для того чтобы создать достаточное количество мест в общежитии, администраторы колледжей или университетов хотят знать, сколько студентов поступят в их учебное заведение в следующем году.
Существуют два общепринятых подхода к прогнозированию: качественный и количественный. Методы качественного прогнозирования особенно важны, если исследователю недоступны количественные данные. Как правило, эти методы носят весьма субъективный характер. Если статистику доступны данные об истории объекта исследования, следует применять методы количественного прогнозирования. Эти методы позволяют предсказать состояние объекта в будущем на основе данных о его прошлом. Методы количественного прогнозирования разделяются на две категории: анализ временных рядов и методы анализа причинно-следственных зависимостей.
Временной ряд - это набор числовых данных, полученных в течение последовательных периодов времени. Метод анализа временных рядов позволяет предсказать значение числовой переменной на основе ее прошлых и настоящих значений. Например, ежедневные котировки акций на Нью-Йоркской фондовой бирже образуют временной ряд. Другим примером временного ряда являются ежемесячные значения индекса потребительских цен, ежеквартальные величины валового внутреннего продукта и ежегодные доходы от продаж какой-нибудь компании.
Методы анализа причинно-следственных зависимостей позволяют определить, какие факторы влияют на значения прогнозируемой переменной. К ним относятся методы множественного регрессионного анализа с запаздывающими переменными, эконометрическое моделирование, анализ лидирующих индикаторов, методы анализа диффузионных индексов и других экономических показателей. Мы расскажем лишь о методах прогнозирования на основе анализа временны х рядов.
Компоненты классической мультипликативной модели временны х рядов
Основное предположение, лежащее в основе анализа временных рядов, состоит в следующем: факторы, влияющие на исследуемый объект в настоящем и прошлом, будут влиять на него и в будущем. Таким образом, основные цели анализа временных рядов заключаются в идентификации и выделении факторов, имеющих значение для прогнозирования. Чтобы достичь этой цели, были разработаны многие математические модели, предназначенные для исследования колебаний компонентов, входящих в модель временного ряда. Вероятно, наиболее распространенной является классическая мультипликативная модель для ежегодных, ежеквартальных и ежемесячных данных. Для демонстрации классической мультипликативной модели временных рядов рассмотрим данные о фактических доходах компании Wm.Wrigley Jr. Company за период с 1982 по 2001 годы (рис. 1).
Рис. 1. График фактического валового дохода компании Wm.Wrigley Jr. Company (млн. долл. в текущих ценах) за период с 1982 по 2001 годы
Как видим, на протяжении 20 лет фактический валовой доход компании имел возрастающую тенденцию. Эта долговременная тенденция называется трендом. Тренд - не единственный компонент временного ряда. Кроме него, данные имеют циклический и нерегулярный компоненты. Циклический компонент описывает колебание данных вверх и вниз, часто коррелируя с циклами деловой активности. Его длина изменяется в интервале от 2 до 10 лет. Интенсивность, или амплитуда, циклического компонента также не постоянна. В некоторые годы данные могут быть выше значения, предсказанного трендом (т.е. находиться в окрестности пика цикла), а в другие годы - ниже (т.е. быть на дне цикла). Любые наблюдаемые данные, не лежащие на кривой тренда и не подчиняющиеся циклической зависимости, называются иррегулярными или случайными компонентами . Если данные записываются ежедневно или ежеквартально, возникает дополнительный компонент, называемый сезонным . Все компоненты временных рядов, характерных для экономических приложений, приведены на рис. 2.

Рис. 2. Факторы, влияющие на временные ряды
Классическая мультипликативная модель временного ряда утверждает, что любое наблюдаемое значение является произведением перечисленных компонентов. Если данные являются ежегодными, наблюдение Y i , соответствующее i -му году, выражается уравнением:
(1) Y i = T i * C i * I i
где T i - значение тренда, C i i -ом году, I i i -ом году.
Если данные измеряются ежемесячно или ежеквартально, наблюдение Y i , соответствующее i-му периоду, выражается уравнением:
(2) Y i = T i *S i *C i *I i
где T i - значение тренда, S i - значение сезонного компонента в i -ом периоде, C i - значение циклического компонента в i -ом периоде, I i - значение случайного компонента в i -ом периоде.
На первом этапе анализа временных рядов строится график данных и выявляется их зависимость от времени. Сначала необходимо выяснить, существует ли долговременное возрастание или убывание данных (т.е. тренд), или временной ряд колеблется вокруг горизонтальной линии. Если тренд отсутствует, то для сглаживания данных можно применить метод скользящих средних или экспоненциального сглаживания.
Сглаживание годовых временных рядов
В сценарии мы упомянули о компании Cabot Corporation. Имея штаб-квартиру в Бостоне, штат Массачусеттс, она специализируется на производстве и продаже химикатов, строительных материалов, продуктов тонкой химии, полупроводников и сжиженного природного газа. Компания имеет 39 заводов в 23 странах. Рыночная стоимость компании составляет около 1,87 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой СВТ. Доходы компании за указанный период приведены на рис. 3.

Рис. 3. Доходы компании Cabot Corporation в 1982–2001 годах (млрд. долл.)
Как видим, долговременная тенденция повышения доходов затемнена большим количеством колебаний. Таким образом, визуальный анализ графика не позволяет утверждать, что данные имеют тренд. В таких ситуациях можно применить методы скользящего среднего или экспоненциального сглаживания.
Скользящие средние. Метод скользящих средних весьма субъективен и зависит от длины периода L , выбранного для вычисления средних значений. Для того чтобы исключить циклические колебания, длина периода должна быть целым числом, кратным средней длине цикла. Скользящие средние для выбранного периода, имеющего длину L , образуют последовательность средних значений, вычисленных для последовательностей длины L . Скользящие средние обозначаются символами MA(L) .
Предположим, что мы хотим вычислить пятилетние скользящие средние значения по данным, измеренным в течение n = 11 лет. Поскольку L = 5, пятилетние скользящие средние образуют последовательность средних значений, вычисленных по пяти последовательным значениям временного ряда. Первое из пятилетних скользящих средних значений вычисляется путем суммирования данных о первых пяти годах с последующим делением на пять:
![]()
Второе пятилетнее скользящее среднее вычисляется путем суммирования данных о годах со 2-го по 6-й с последующим делением на пять:
![]()
Этот процесс продолжается, пока не будет вычислено скользящее среднее для последних пяти лет. Работая с годовыми данными, следует полагать число L (длину периода, выбранного для вычисления скользящих средних) нечетным. В этом случае невозможно вычислить скользящие средние для первых (L – 1)/2 и последних (L – 1)/2 лет. Следовательно, при работе с пятилетними скользящими средними невозможно выполнить вычисления для первых двух и последних двух лет. Год, для которого вычисляется скользящее среднее, должен находиться в середине периода, имеющего длину L . Если n = 11, a L = 5, первое скользящее среднее должно соответствовать третьему году, второе - четвертому, а последнее - девятому. На рис. 4 показаны графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation за период с 1982 по 2001 годы.

Рис. 4. Графики 3- и 7-летних скользящих средних, вычисленные для доходов компании Cabot Corporation
Обратите внимание на то, что при вычислении трехлетних скользящих средних проигнорированы наблюдаемые значения, соответствующие первому и последнему годам. Аналогично при вычислении семилетних скользящих средних нет результатов для первых и последних трех лет. Кроме того, семилетние скользящие средние намного больше сглаживают временной ряд, чем трехлетние. Это происходит потому, что семилетним скользящим средним соответствует более долгий период. К сожалению, чем больше длина периода, тем меньшее количество скользящих средних можно вычислить и представить на графике. Следовательно, больше семи лет для вычисления скользящих средних выбирать нежелательно, поскольку из начала и конца графика выпадет слишком много точек, что исказит форму временного ряда.
Экспоненциальное сглаживание. Для выявления долговременных тенденций, характеризующих изменения данных, кроме скользящих средних, применяется метод экспоненциального сглаживания. Этот метод позволяет также делать краткосрочные прогнозы (в рамках одного периода), когда наличие долговременных тенденций остается под вопросом. Благодаря этому метод экспоненциального сглаживания обладает значительным преимуществом над методом скользящих средних.
Метод экспоненциального сглаживания получил свое название от последовательности экспоненциально взвешенных скользящих средних. Каждое значение в этой последовательности зависит от всех предыдущих наблюдаемых значений. Еще одно преимущество метода экспоненциального сглаживания над методом скользящего среднего заключается в том, что при использовании последнего некоторые значения отбрасываются. При экспоненциальном сглаживании веса, присвоенные наблюдаемым значениям, убывают со временем, поэтому после выполнения вычислений наиболее часто встречающиеся значения получат наибольший вес, а редкие величины - наименьший. Несмотря на громадное количество вычислений, Excel позволяет реализовать метод экспоненциального сглаживания.
Уравнение, позволяющее сгладить временной ряд в пределах произвольного периода времени i , содержит три члена: текущее наблюдаемое значение Y i , принадлежащее временному ряду, предыдущее экспоненциально сглаженное значение E i –1 и присвоенный вес W .
(3) E 1 = Y 1 E i = WY i + (1 – W)E i–1 , i = 2, 3, 4, …
где E i – значение экспоненциально сглаженного ряда, вычисленное для i -го периода, E i –1 – значение экспоненциально сглаженного ряда, вычисленное для (i – 1)-гo периода, Y i – наблюдаемое значение временного ряда в i -ом периоде, W – субъективный вес, или сглаживающий коэффициент (0 < W < 1).
Выбор сглаживающего коэффициента, или веса, присвоенного членам ряда, является принципиально важным, поскольку он непосредственно влияет на результат. К сожалению, этот выбор до некоторой степени субъективен. Если исследователь хочет просто исключить из временного ряда нежелательные циклические или случайные колебания, следует выбирать небольшие величины W (близкие к нулю). С другой стороны, если временной ряд используется для прогнозирования, необходимо выбрать большой вес W (близкий к единице). В первом случае четко проявляются долговременные тенденции временного ряда. Во втором случае повышается точность краткосрочного прогнозирования (рис. 5).

Рис. 5 Графики экспоненциально сглаженного временного ряда (W=0,50 и W=0,25) для данных о доходах компании Cabot Corporation за период с 1982 по 2001 годы; формулы расчета см. в файле Excel
Экспоненциально сглаженное значение, полученное для i -го временного интервала, можно использовать в качестве оценки предсказанного значения в (i +1)-м интервале:
![]()
Для предсказания доходов компании Cabot Corporation в 2002 году на основе экспоненциально сглаженного временного ряда, соответствующего весу W = 0,25, можно использовать сглаженное значение, вычисленное для 2001 года. Из рис. 5 видно, что эта величина равна 1651,0 млн. долл. Когда станут доступными данные о доходах компании в 2002 году, можно применить уравнение (3) и предсказать уровень доходов в 2003 году, используя сглаженное значение доходов в 2002 году:
Пакет анализа Excel способен построить график экспоненциального сглаживания в один клик. Пройдите по меню Данные → Анализ данных и выберите опцию Экспоненциальное сглаживание (рис. 6). В открывшемся окне Экспоненциальное сглаживание задайте параметры. К сожалению, процедура позволяет построить только один сглаженный ряд, поэтому, если вы хотите «поиграть» с параметром W , повторите процедуру.

Рис. 6. Построение графика экспоненциального сглаживания с помощью Пакета анализа
Вычисление трендов с помощью метода наименьших квадратов и прогнозирование
Среди компонентов временного ряда чаще других исследуется тренд. Именно тренд позволяет делать краткосрочные и долгосрочные прогнозы. Для выявления долговременной тенденции изменения временного ряда обычно строят график, на котором наблюдаемые данные (значения зависимой переменной) откладываются на вертикальной оси, а временные интервалы (значения независимой переменной) - на горизонтальной. В этом разделе мы опишем процедуру выявления линейного, квадратичного и экспоненциального тренда с помощью метода наименьших квадратов.
Модель линейного тренда является простейшей моделью, применяемой для прогнозирования: Y i = β 0 + β 1 X i + ε i . Уравнение линейного тренда:
![]()
При заданном уровне значимости α нулевая гипотеза отклоняется, если тестовая t -статистика больше верхнего или меньше нижнего критического уровня t -распределения. Иначе говоря, решающее правило формулируется следующим образом: если t > t U или t < t L , нулевая гипотеза Н 0 отклоняется, в противном случае нулевая гипотеза не отклоняется (рис. 14).

Рис. 14. Области отклонения гипотезы для двустороннего критерия значимости параметра авторегрессии А р , имеющего наивысший порядок
Если нулевая гипотеза (А р = 0) не отклоняется, значит, выбранная модель содержит слишком много параметров. Критерий позволяет отбросить старший член модели и оценить авторегрессионную модель порядка р–1 . Эту процедуру следует продолжать до тех пор, пока нулевая гипотеза Н 0 не будет отклонена.
- Выберите порядок р оцениваемой авторегрессионной модели с учетом того, что t -критерий значимости имеет n –2р–1 степеней свободы.
- Сформируйте последовательность переменных р «с запаздыванием» так, чтобы первая переменная запаздывала на один временной интервал, вторая - на два и так далее. Последнее значение должно запаздывать на р временных интервалов (см. рис. 15).
- Примените Пакет анализа Excel для вычисления регрессионной модели, содержащей все р значений временного ряда с запаздыванием.
- Оцените значимость параметра А Р , имеющего наивысший порядок: а) если нулевая гипотеза отклоняется, в авторегрессионную модель можно включать все р параметров; б) если нулевая гипотеза не отклоняется, отбросьте р -ю переменную и повторите п.3 и 4 для новой модели, включающей р–1 параметр. Проверка значимости новой модели основана на t -критерии, количество степеней свободы определяется новым количеством параметров.
- Повторяйте п.3 и 4, пока старший член авторегрессионной модели не станет статистически значимым.
Чтобы продемонстрировать авторегрессионное моделирование, вернемся к анализу временного ряда реальных доходов компании Wm. Wrigley Jr. На рис. 15 показаны данные, необходимые для построения авторегрессионных моделей первого, второго и третьего порядка. Для построения модели третьего порядка необходимы все столбцы этой таблицы. При построении авторегрессионной модели второго порядка последний столбец игнорируется. При построении авторегрессионной модели первого порядка игнорируются два последних столбца. Таким образом, при построении авторегрессионных моделей первого, второго и третьего порядка из 20 переменных исключаются одна, две и три соответственно.

Выбор наиболее точной авторегрессионной модели начинается с модели третьего порядка. Для корректной работы Пакета анализа следует в качестве входного интервала Y указать диапазон В5:В21, а входного интервала для Х – С5:Е21. Данные анализа приведены на рис. 16.

Проверим значимость параметра А 3 , имеющего наивысший порядок. Его оценка а 3 равна –0,006 (ячейка С20 на рис. 16), а стандартная ошибка равна 0,326 (ячейка D20). Для проверки гипотез Н 0: А 3 = 0 и Н 1: А 3 ≠ 0 вычислим t -статистику:

t -критерия с n–2p–1 = 20–2*3–1 = 13 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;13) = –2,160; t U =СТЬЮДЕНТ.ОБР(0,975;13) = +2,160. Поскольку –2,160 < t = –0,019 < +2,160 и р = 0,985 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр третьего порядка не имеет статистической значимости в авторегрессионной модели и должен быть удален.
Повторим анализ для авторегрессионной модели второго порядка (рис. 17). Оценка параметра, имеющего наивысший порядок, а 2 = –0,205, а ее стандартная ошибка равна 0,276. Для проверки гипотез Н 0: А 2 = 0 и Н 1: А 2 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*2–1 = 15 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;15) = –2,131; t U =СТЬЮДЕНТ.ОБР(0,975;15) = +2,131. Поскольку –2,131 < t = –0,744 < –2,131 и р = 0,469 > α = 0,05, нулевую гипотезу Н 0 отклонять нельзя. Таким образом, параметр второго порядка не является статистически значимым, и его следует удалить из модели.
Повторим анализ для авторегрессионной модели первого порядка (рис. 18). Оценка параметра, имеющего наивысший порядок, а 1 = 1,024, а ее стандартная ошибка равна 0,039. Для проверки гипотез Н 0: А 1 = 0 и Н 1: А 1 ≠ 0 вычислим t -статистику:


При уровне значимости α = 0,05, критические величины двухстороннего t -критерия с n–2p–1 = 20–2*1–1 = 17 степенями свободы равны: t L =СТЬЮДЕНТ.ОБР(0,025;17) = –2,110; t U =СТЬЮДЕНТ.ОБР(0,975;17) = +2,110. Поскольку –2,110 < t = 26,393 < –2,110 и р = 0,000 < α = 0,05, нулевую гипотезу Н 0 следует отклонить. Таким образом, параметр первого порядка является статистически значимым, и его нельзя удалять из модели. Итак, модель авторегрессии первого порядка лучше других аппроксимирует исходные данные. Используя оценки а 0 = 18,261, а 1 = 1,024 и значение временного ряда за последний год - Y 20 = 1 371,88, можно предсказать величину реальных доходов компании Wm. Wrigley Jr. Company в 2002 г.:
Выбор адекватной модели прогнозирования
Выше были описаны шесть методов прогнозирования значений временного ряда: модели линейного, квадратичного и экспоненциального трендов и авторегрессионные модели первого, второго и третьего порядков. Существует ли оптимальная модель? Какую из шести описанных моделей следует применять для прогнозирования значения временного ряда? Ниже перечислены четыре принципа, которыми необходимо руководствоваться при выборе адекватной модели прогнозирования. Эти принципы основаны на оценках точности моделей. При этом предполагается, что значения временного ряда можно предсказать, изучая его предыдущие значения.
Принципы выбора моделей для прогнозирования:
- Выполните анализ остатков.
- Оцените величину остаточной ошибки с помощью квадратов разностей.
- Оцените величину остаточной ошибки с помощью абсолютных разностей.
- Руководствуйтесь принципом экономии.
Анализ остатков. Напомним, что остатком называется разность между предсказанным и наблюдаемым значением. Построив модель для временного ряда, следует вычислить остатки для каждого из n интервалов. Как показано на рис. 19, панель А, если модель является адекватной, остатки представляют собой случайный компонент временного ряда и, следовательно, распределены нерегулярно. С другой стороны, как показано на остальных панелях, если модель не адекватна, остатки могут иметь систематическую зависимость, не учитывающую либо тренд (панель Б), либо циклический (панель В), либо сезонный компонент (панель Г).

Рис. 19. Анализ остатков
Измерение абсолютной и среднеквадратичной остаточных погрешностей. Если анализ остатков не позволяет определить единственную адекватную модель, можно воспользоваться другими методами, основанными на оценке величины остаточной погрешности. К сожалению, статистики не пришли к консенсусу относительно наилучшей оценки остаточных погрешностей моделей, применяемых для прогнозирования. Исходя из принципа наименьших квадратов, можно сначала провести регрессионный анализ и вычислить стандартную ошибку оценки S XY . При анализе конкретной модели эта величина представляет собой сумму квадратов разностей между фактическим и предсказанным значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки равна нулю. С другой стороны, если модель плохо аппроксимирует значения временного ряда в предыдущие моменты времени, стандартная ошибка оценки велика. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальную стандартную ошибку оценки S XY .
Основным недостатком такого подхода является преувеличение ошибок при прогнозировании отдельных значений. Иначе говоря, любая большая разность между величинами Y i и Ŷ i при вычислении суммы квадратов ошибок SSE возводится в квадрат, т.е. увеличивается. По этой причине многие статистики предпочитают применять для оценки адекватности модели прогнозирования среднее абсолютное отклонение (mean absolute deviation - MAD):

При анализе конкретных моделей величина MAD представляет собой среднее значение модулей разностей между фактическим и предсказанными значениями временного ряда. Если модель идеально аппроксимирует значения временного ряда в предыдущие моменты времени, среднее абсолютное отклонение равно нулю. С другой стороны, если модель плохо аппроксимирует такие значения временного ряда, среднее абсолютное отклонение велико. Таким образом, анализируя адекватность нескольких моделей, можно выбрать модель, имеющую минимальное среднее абсолютное отклонение.
Принцип экономии. Если анализ стандартных ошибок оценок и средних абсолютных отклонений не позволяет определить оптимальную модель, можно воспользоваться четвертым методом, основанным на принципе экономии. Этот принцип утверждает, что из нескольких равноправных моделей следует выбирать простейшую.
Среди шести рассмотренных в главе моделей прогнозирования наиболее простыми являются линейная и квадратичная регрессионные модели, а также авторегрессионная модель первого порядка. Остальные модели намного сложнее.
Сравнение четырех методов прогнозирования. Для иллюстрации процесса выбора оптимальной модели вернемся к временному ряду, состоящему из величин реального дохода компании Wm. Wrigley Jr. Company. Сравним четыре модели: линейную, квадратичную, экспоненциальную и авторегрессионную модель первого порядка. (Авторегрессионные модели второго и третьего порядка лишь незначительно улучшают точность прогнозирования значений данного временного ряда, поэтому их можно не рассматривать.) На рис. 20 показаны графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel. Делая выводы на основе этих графиков, следует быть осторожным, поскольку временной ряд содержит только 20 точек. Методы построения см. соответствующий лист Excel-файла.

Рис. 20. Графики остатков, построенные при анализе четырех методов прогнозирования с помощью Пакета анализа Excel
Ни одна модель, кроме авторегрессионой модели первого порядка, не учитывает циклический компонент. Именно эта модель лучше других аппроксимирует наблюдения и характеризуется наименее систематической структурой. Итак, анализ остатков всех четырех методов показал, что наилучшей является авторегрессионная модель первого порядка, а линейная, квадратичная и экспоненциальная модели имеют меньшую точность. Чтобы убедиться в этом, сравним величины остаточных погрешностей этих методов (рис. 21). С методикой расчетов можно ознакомиться, открыв Excel-файл. На рис. 21 указаны фактические значения Y i (колонка Реальный доход ), предсказанные значения Ŷ i , а также остатки е i для каждой из четырех моделей. Кроме того, показаны значения S YX и MAD . Для всех четырех моделей величинs S YX и MAD примерно одинаковые. Экспоненциальная модель является относительно худшей, а линейная и квадратичная модели превосходят ее по точности. Как и ожидалось, наименьшие величины S YX и MAD имеет авторегрессионная модель первого порядка.

Рис. 21. Сравнение четырех методов прогнозирования с помощью показателей S YX и MAD
Выбрав конкретную модель прогнозирования, необходимо внимательно следить за дальнейшими изменениями временного ряда. Помимо всего прочего, такая модель создается, чтобы правильно предсказывать значения временного ряда в будущем. К сожалению, такие модели прогнозирования плохо учитывают изменения в структуре временного ряда. Совершенно необходимо сравнивать не только остаточную погрешность, но и точность прогнозирования будущих значений временного ряда, полученную с помощью других моделей. Измерив новую величину Y i в наблюдаемом интервале времени, ее необходимо тотчас же сравнить с предсказанным значением. Если разница слишком велика, модель прогнозирования следует пересмотреть.
Прогнозирование временны х рядов на основе сезонных данных
До сих пор мы изучали временные ряды, состоящие из годовых данных. Однако многие временные ряды состоят из величин, измеряемых ежеквартально, ежемесячно, еженедельно, ежедневно и даже ежечасно. Как показано на рис. 2, если данные измеряются ежемесячно или ежеквартально, следует учитывать сезонный компонент. В этом разделе мы рассмотрим методы, позволяющие прогнозировать значения таких временных рядов.
В сценарии, описанном в начале главы, упоминалась компания Wal-Mart Stores, Inc. Рыночная капитализация компании 229 млрд. долл. Ее акции котируются на Нью-Йоркской фондовой бирже под аббревиатурой WMT. Финансовый год компании заканчивается 31 января, поэтому в четвертый квартал 2002 года включаются ноябрь и декабрь 2001 года, а также январь 2002 года. Временной ряд квартальных доходов компании приведен на рис. 22.

Рис. 22. Квартальные доходы компании Wal-Mart Stores, Inc. (млн. долл.)
Для таких квартальных рядов, как этот, классическая мультипликативная модель, кроме тренда, циклического и случайного компонента, содержит сезонный компонент: Y i = T i * S i * C i * I i
Прогнозирование месячных и временны х рядов с помощью метода наименьших квадратов. Регрессионная модель, включающая сезонный компонент, основана на комбинированном подходе. Для вычисления тренда применяется метод наименьших квадратов, описанный ранее, а для учета сезонного компонента - категорийная переменная (подробнее см. раздел Регрессионные модели с фиктивной переменной и эффекты взаимодействия ). Для аппроксимации временных рядов с учетом сезонных компонентов используется экспоненциальная модель. В модели, аппроксимирующей квартальный временной ряд, для учета четырех кварталов нам понадобились три фиктивные переменные Q 1 , Q 2 и Q 3 , а в модели для месячного временного ряда 12 месяцев представляются с помощью 11 фиктивных переменных. Поскольку в этих моделях в качестве отклика используется переменная logY i , а не Y i , для вычисления настоящих регрессионных коэффициентов необходимо выполнить обратное преобразование.
Чтобы проиллюстрировать процесс построения модели, аппроксимирующей квартальный временной ряд, вернемся к доходам компании Wal-Mart. Параметры экспоненциальной модели, полученные с помощью Пакета анализа Excel, показаны на рис. 23.

Рис. 23. Регрессионный анализ квартальных доходов компании Wal-Mart Stores, Inc.
Видно, что экспоненциальная модель довольно хорошо аппроксимирует исходные данные. Коэффициент смешанной корреляции r 2 равен 99,4% (ячейки J5), скорректированный коэффициент смешанной корреляции - 99,3% (ячейки J6), тестовая F -статистика - 1 333,51 (ячейки M12), а р -значение равно 0,0000. При уровне значимости α = 0,05, каждый регрессионный коэффициент в классической мультипликативной модели временного ряда является статистически значимым. Применяя к ним операцию потенцирования, получаем следующие параметры:

Коэффициенты ![]() интерпретируются следующим образом.
интерпретируются следующим образом.
Используя регрессионные коэффициенты b i , можно предсказать доход, полученный компанией в конкретном квартале. Например, предскажем доход компании для четвертого квартала 2002 года (X i = 35):
log = b 0 + b 1 Х i = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Таким образом, согласно прогнозу в четвертом квартале 2002 года компания должна была получить доход, равный 67 млрд. долл. (вряд ли следует делать прогноз с точностью до миллиона). Для того чтобы распространить прогноз на период времени, находящийся за пределами временного ряда, например, на первый квартал 2003 года (X i = 36, Q 1 = 1), необходимо выполнить следующие вычисления:
logŶ i = b 0 + b 1 Х i + b 2 Q 1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Индексы
Индексы используются в качестве индикаторов, реагирующих на изменения экономической ситуации или деловой активности. Существуют многочисленные разновидности индексов, в частности, индексы цен, количественные индексы, ценностные индексы и социологические индексы. В данном разделе мы рассмотрим лишь индекс цен. Индекс - величина некоторого экономического показателя (или группы показателей) в конкретный момент времени, выраженный в процентах от его значения в базовый момент времени.
Индекс цен. Простой индекс цен отражает процентное изменение цены товара (или группы товаров) в течение заданного периода времени по сравнению с ценой этого товара (или группы товаров) в конкретный момент времени в прошлом. При вычислении индекса цен прежде всего следует выбрать базовый промежуток времени - интервал времени в прошлом, с которым будут производиться сравнения. При выборе базового промежутка времени для конкретного индекса периоды экономической стабильности являются более предпочтительными по сравнению с периодами экономического подъема или спада. Кроме того, базовый промежуток не должен быть слишком удаленным во времени, чтобы на результаты сравнения не слишком сильно влияли изменения технологии и привычек потребителей. Индекс цен вычисляется по формуле:

где I i - индекс цен в i -м году, Р i - цена в i -м году, Р баз - цена в базовом году.
Индекс цен - процентное изменение цены товара (или группы товаров) в заданный период времени по отношению к цене товара в базовый момент времени. В качестве примера рассмотрим индекс цен на неэтилированный бензин в США в промежутке времени с 1980 по 2002 г. (рис. 24). Например:


Рис. 24. Цена галлона неэтилированного бензина и простой индекс цен в США с 1980 по 2002 г. (базовые годы - 1980 и 1995)
Итак, в 2002 г. цена неэтилированного бензина в США была на 4,8% больше, чем в 1980 г. Анализ рис. 24 показывает, что индекс цен в 1981 и 1982 гг. был больше индекса цен в 1980 г., а затем вплоть до 2000 года не превышал базового уровня. Поскольку в качестве базового периода выбран 1980 г., вероятно, имеет смысл выбрать более близкий год, например, 1995 г. Формула для пересчета индекса по отношению к новому базовому промежутку времени:

где I новый - новый индекс цен, I старый - старый индекс цен, I новая база – значение индекса цен в новом базовом году при расчете для старого базового года.
Предположим, что в качестве новой базы выбран 1995 год. Используя формулу (10), получаем новый индекс цен для 2002 года:
Итак, в 2002 г. неэтилированный бензин в США стоил на 13,9% больше, чем в 1995 г.
Невзвешенные составные индексы цен. Несмотря на то что индекс цен на любой отдельный товар представляет несомненный интерес, более важным является индекс цен на группу товаров, позволяющий оценить стоимость и уровень жизни большого количества потребителей. Невзвешенный составной индекс цен, определенный формулой (11), приписывает каждому отдельному виду товаров одинаковый вес. Составной индекс цен отражает процентное изменение цены группы товаров (часто называемой потребительской корзиной) в заданный период времени по отношению к цене этой группы товаров в базовый момент времени.

где t i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - сумма цен на каждый из n товаров в период времени t , - сумма цен на каждый из n товаров в нулевой период времени, - величина невзвешенного составного индекса в период времени t .
На рис. 25 представлены средние цены на три вида фруктов за период с 1980 по 1999 гг. Для вычисления невзвешенного составного индекса цен в разные годы применяется формула (11), считая базовым 1980 год.
Итак, в 1999 г. суммарная цена фунта яблок, фунта бананов и фунта апельсинов на 59,4% превышала суммарную цену на эти фрукты в 1980 г.

Рис. 25. Цены (в долл.) на три вида фруктов и невзвешенный составной индекс цен
Невзвешенный составной индекс цен выражает изменения цен на всю группу товаров с течением времени. Несмотря на то что этот индекс легко вычислять, у него есть два явных недостатка. Во-первых, при вычислении этого индекса все виды товаров считаются одинаково важными, поэтому дорогие товары приобретают излишнее влияние на индекс. Во-вторых, не все товары потребляются одинаково интенсивно, поэтому изменения цен на мало потребляемые товары слишком сильно влияют на невзвешенный индекс.
Взвешенные составные индексы цен. Из-за недостатков невзвешенных индексов цен более предпочтительными являются взвешенные индексы цен, учитывающие различия цен и уровней потребления товаров, образующих потребительскую корзину. Существуют два типа взвешенных составных индексов цен. Индекс цен Лапейрэ , определенный формулой (12), использует уровни потребления в базовом году. Взвешенный составной индекс цен позволяет учесть уровни потребления товаров, образующих потребительскую корзину, присваивая каждому товару определенный вес.

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n i в нулевой период времени, - значение индекса Лапейрэ в период времени t .
Вычисления индекса Лапейрэ показаны на рис. 26; в качестве базового используется 1980 год.

Рис. 26. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Лапейрэ
Итак, индекс Лапейрэ в 1999 г. равен 154,2. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 54,2% дороже, чем в 1980 году. Обратите внимание на то, что этот индекс меньше невзвешенного индекса, равного 159,4, поскольку цены на апельсины - фрукты, потребляемые меньше остальных, - выросли больше, чем цена яблок и бананов. Иначе говоря, поскольку цены на фрукты, потребляемые наиболее интенсивно, выросли меньше, чем цены на апельсины, индекс Лапейрэ меньше невзвешенного составного индекса.
Индекс цен Пааше использует уровни потребления товара в текущем, а не базовом периоде времени. Следовательно, индекс Пааше более точно отражает полную стоимость потребления товаров в заданный момент времени. Однако этот индекс имеет два существенных недостатка. Во-первых, как правило, текущие уровни потребления трудно определить. По этой причине многие популярные индексы используют индекс Лапейрэ, а не индекс Пааше. Во-вторых, если цена некоторого конкретного товара, входящего в потребительскую корзину, резко возрастает, покупатели снижают уровень его потребления по необходимости, а не вследствие изменения вкусов. Индекс Пааше вычисляется по формуле:

где t - период времени (0, 1, 2, …), i - номер товара (1, 2, …, n ), n - количество товаров в рассматриваемой группе, - количество единиц товара i в нулевой период времени, - значение индекса Пааше в период времени t .
Вычисления индекса Пааше показаны на рис. 27; в качестве базового используется 1980 год.

Рис. 27. Цены (в долл.), количество (потребление в фунтах на душу населения) трех видов фруктов и индекс Пааше
Итак, индекс Пааше в 1999 г. равен 147,0. Это свидетельствует от том, что в 1999 году эти три вида фруктов были на 47,0% дороже, чем в 1980 году.
Некоторые популярные индексы цен. В бизнесе и экономике используется несколько индексов цен. Наиболее популярным является индекс потребительских цен (Consumer Index Price - CPI). Официально этот индекс называется CPI-U, чтобы подчеркнуть, что он вычисляется для городов (urban), хотя, как правило, его называют просто CPI. Этот индекс ежемесячно публикуется Бюро статистики труда (U. S. Bureau of Labor Statistics) в качестве основного инструмента для измерения стоимости жизни в США. Индекс потребительских цен является составным и взвешенным по методу Лапейрэ. При его вычислении используются цены 400 наиболее широко потребляемых продуктов, видов одежды, транспортных, медицинских и коммунальных услуг. В данный момент при вычислении этого индекса в качестве базового используется период 1982–1984 гг. (рис. 28). Важной функцией индекса CPI является его использование в качестве дефлятора. Индекс CPI используется для пересчета фактических цен в реальные путем умножения каждой цены на коэффициент 100/CPI. Расчеты показывают, что за последние 30 лет среднегодовые темпы инфляции в США составили 2,9%.

Рис. 28. Динамика Consumer Index Price; полные данные см. Excel-файл
Другим важным индексом цен, публикуемым Бюро статистики труда, является индекс цен производителей (Producer Price Index - PPI). Индекс PPI является взвешенным составным индексом, использующим метод Лапейрэ для оценки изменения цен товаров, продаваемых их производителями. Индекс PPI является лидирующим индикатором для индекса CPI. Иначе говоря, увеличение индекса PPI приводит к увеличению индекса CPI, и наоборот, уменьшение индекса PPI приводит к уменьшению индекса CPI. Финансовые индексы, такие как индекс Доу-Джонса для акций промышленных предприятий (Dow Jones Industrial Average - DJIA), S&P 500 и NASDAQ, используются для оценки изменения стоимости акций в США. Многие индексы позволяют оценить прибыльность международных фондовых рынков. К таким индексам относятся индекс Nikkei в Японии, Dax 30 в Германии и SSE Composite в Китае.
Ловушки, связанные с анализом временны х рядов
Значение методологии, использующей информацию о прошлом и настоящем для того, чтобы прогнозировать будущее, более двухсот лет назад красноречиво описал государственный деятель Патрик Генри: «У меня есть лишь одна лампа, освещающая путь, - мой опыт. Только знание прошлого позволяет судить о будущем».
Анализ временных рядов основан на предположении, что факторы, влиявшие на деловую активность в прошлом и влияющие в настоящем, будут действовать и в будущем. Если это правда, анализ временных рядов представляет собой эффективное средство прогнозирования и управления. Однако критики классических методов, основанных на анализе временных рядов, утверждают, что эти методы слишком наивны и примитивны. Иначе говоря, математическая модель, учитывающая факторы, действовавшие в прошлом, не должна механически экстраполировать тренды в будущее без учета экспертных оценок, опыта деловой активности, изменения технологии, а также привычек и потребностей людей. Пытаясь исправить это положение, в последние годы специалисты по эконометрии разрабатывали сложные компьютерные модели экономической активности, учитывающие перечисленные выше факторы.
Тем не менее, методы анализа временных рядов представляют собой превосходный инструмент прогнозирования (как краткосрочного, так и долгосрочного), если они применяются правильно, в сочетании с другими методами прогнозирования, а также с учетом экспертных оценок и опыта.
Резюме. В заметке с помощью анализа временных рядов разработаны модели для прогнозирования доходов трех компаний: Wm. Wrigley Jr. Company, Cabot Corporation и Wal-Mart. Описаны компоненты временного ряда, а также несколько подходов к прогнозированию годовых временных рядов - метод скользящих средних, метод экспоненциального сглаживания, линейная, квадратичная и экспоненциальная модели, а также авторегрессионная модель. Рассмотрена регрессионная модель, содержащая фиктивные переменные, соответствующие сезонному компоненту. Показано применение метода наименьших квадратов для прогнозирования месячных и квартальных временных рядов (рис. 29).
Р степеней свободы утрачиваются при сравнении значений временного ряда.
Введение
В данной главе рассматриваются задачи описания упорядоченных данных, полученных последовательно (во времени). Вообще говоря, упорядоченность может иметь место не только во времени, но и в пространстве, например, диаметр нити как функция её длины (одномерный случай), значение температуры воздуха как функция пространственных координат (трёхмерный случай).
В отличие от регрессионного анализа, где порядок строк в матрице наблюдений может быть произвольным, во временных рядах важна упорядоченность, а следовательно, интерес представляет взаимосвязь значений, относящихся к разным моментам времени.
Если значения ряда известны в отдельные моменты времени, то такой ряд называют дискретным , в отличие от непрерывного , значения которого известны в любой момент времени. Интервал между двумя последовательными моментами времени назовём тактом (шагом) . Здесь будут рассматриваться в основном дискретные временные ряды с фиксированной протяжённостью такта, принимаемой за единицу счёта. Заметим, что временные ряды экономических показателей, как правило, дискретны.
Значения ряда могут быть измеряемыми непосредственно (цена, доходность, температура), либо агрегированными (кумулятивными) , например, объём выпуска; расстояние, пройдённое грузоперевозчиками за временной такт.
Если значения ряда определяются детерминированной математической функцией, то ряд называют детерминированным . Если эти значения могут быть описаны лишь с привлечением вероятностных моделей, то временной ряд называют случайным .
Явление, протекающее во времени, называют процессом , поэтому можно говорить о детерминированном или случайном процессах. В последнем случае используют часто термин “стохастический процесс” . Анализируемый отрезок временного ряда может рассматриваться как частная реализация (выборка) изучаемого стохастического процесса, генерируемого скрытым вероятностным механизмом.
Временные ряды возникают во многих предметных областях и имеют различную природу. Для их изучения предложены различные методы, что делает теорию временных рядов весьма разветвленной дисциплиной. Так, в зависимости от вида временных рядов можно выделить такие разделы теории анализа временных рядов:
– стационарные случайные процессы, описывающие последовательности случайных величин, вероятностные свойства которых не изменяются во времени. Подобные процессы широко распространены в радиотехнике, метереологии, сейсмологии и т. д.
– диффузионные процессы, имеющие место при взаимопроникновении жидкостей и газов.
– точечные процессы, описывающие последовательности событий, таких как поступление заявок на обслуживание, стихийных и техногенных катастроф. Подобные процессы изучаются в теории массового обслуживания.
Мы ограничимся рассмотрением прикладных аспектов анализа временных рядов, которые полезны при решении практических задач в экономике, финансах. Основной упор будет сделан на методы подбора математической модели для описания временного ряда и прогнозирования его поведения.
1.Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
– описание характерных особенностей ряда в сжатой форме;
– построение модели временного ряда;
– предсказание будущих значений на основе прошлых наблюдений;
– управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
1) графическое представление и описание поведения ряда;
2) выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
3) исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
4) построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
5) прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
1) корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
2) спектральный анализ, позволяющий находить периодические составляющие временного ряда;
3) методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
5) методы прогнозирования.
2.Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.). Под детерминированной составляющей временного ряда
понимают числовую последовательность , элементы которой вычисляются по определенному правилу как функция времени t . Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом – плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
1) тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
2) сезонный эффект s , связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Рис. Структурные компоненты временного ряда.
Типичные примеры сезонного эффекта: изменение загруженности автотрассы в течение суток, по дням недели, временам года, пик продаж товаров для школьников в конце августа - начале сентября. Сезонная компонента со временем может меняться, либо носить плавающий характер. Так на графике объема перевозок авиалайнерами (см рис.) видно, что локальные пики, приходящиеся на праздник Пасхи «плавают» из-за изменчивости ее сроков.
Циклическая компонента c , описывающая длительные периоды относительного подъема и спада и состоящая из циклов переменной длительности и амплитуды. Подобная компонента весьма характерна для рядов макроэкономических показателей. Циклические изменения обусловлены здесь взаимодействием спроса и предложения, а также наложением таких факторов, как истощение ресурсов, погодные условия, изменения в налоговой политике и т. п. Отметим, что циклическую компоненту крайне трудно идентифицировать формальными методами, исходя только из данных изучаемого ряда.
«Взрывная» компонента i , иначе интервенция, под которой понимают существенное кратковременное воздействие на временной ряд. Примером интервенции могут служить события «черного вторника» 1994г., когда курс доллара за день вырос на несколько десятков процентов.
Случайная составляющая ряда отражает воздействие многочисленных факторов случайного характера и может иметь разнообразную структуру, начиная от простейшей в виде «белого шума» до весьма сложных, описываемых моделями авторегрессии-скользящего среднего (подробнее дальше).
После выделения структурных компонент необходимо специфицировать форму их вхождения во временной ряд. На верхнем уровне представления с выделением лишь детерминированной и случайной составляющих обычно используют аддитивную либо мультипликативную модели.
Аддитивная модель имеет вид
;мультипликативная –
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.

Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».

Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:

Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.
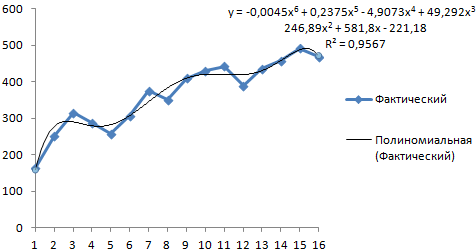
R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.

Получаем достаточно оптимистичный результат:
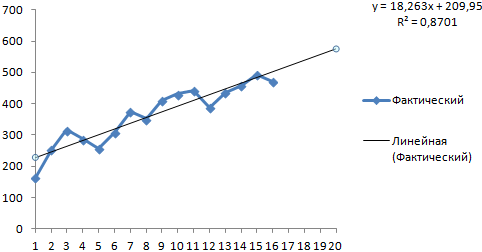
В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.
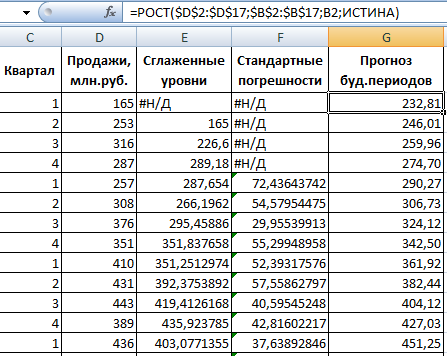
Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
Цели анализа временных рядов. При практическом изучении временных радов на основании экономических данных на определенном промежутке времени эконометрист должен сделать выводы о свойствах этого ряда и о вероятностном механизме, порождающем этот ряд. Чаще всего при изучении временных рядов ставятся следующие цели:
1. Краткое (сжатое) описание характерных особенностей ряда.
2. Подбор статистической модели, описывающей временной ряд.
3. Предсказание будущих значений на основе прошлых наблюдений.
4. Управление процессом, порождающим временной ряд.
На практике эти и подобные цели достижимы далеко не всегда и далеко не в полной мере. Часто этому препятствует недостаточный объем наблюдений из-за ограниченного времени наблюдений. Еще чаще – изменяющаяся с течением времени статистическая структура временного ряда.
Стадии анализа временных рядов. Обычно при практическом анализе временных рядов последовательно проходят следующие этапы:
1. Графическое представление и описание поведения временного рада.
2. Выделение и удаление закономерных составляющих временного рада, зависящих от времени: тренда, сезонных и циклических составляющих.
3. Выделение и удаление низко- или высокочастотных составляющих процесса (фильтрация).
4. Исследование случайной составляющей временного ряда, оставшейся после удаления перечисленных выше составляющих.
5. Построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности.
6. Прогнозирование будущего развития процесса, представленного временным рядом.
7. Исследование взаимодействий между различными временными радами.
Для решения этих задач существует большое количество различных методов. Из них наиболее распространенными являются следующие:
8. Корреляционный анализ, позволяющий выявить существенные периодические зависимости и их лаги (задержки) внутри одного процесса (автокорреляция) или между несколькими процессами (кросскорреляция).
9. Спектральный анализ, позволяющий находить периодические и квазипериодические составляющие временного ряда.
10. Сглаживание и фильтрация, предназначенные для преобразования временных рядов с целью удаления из них высокочастотных или сезонных колебаний.
12. Прогнозирование, позволяющее на основе подобранной модели поведения временного рада предсказывать его значения в будущем.
Модели тренда
простейшие модели тренда. Приведем модели трендов, наиболее часто используемые при анализе экономических временных рядов, а также во многих других областях. Во-первых, это простая линейная модель
где а 0 , а 1 – коэффициенты модели тренда;
t – время.
В качестве единицы времени, может быть, час, день (сутки), неделя, месяц, квартал или год. Модель 269, несмотря на свою простоту, оказывается полезной во многих реальных задачах. Если нелинейный характер тренда очевиден, то может подойти одна из следующих моделей:
1. Полиномиальная:
(270)
где значение степени полинома п в практических задачах редко превышает 5;
2. Логарифмическая:
Эта модель чаще всего применяется для данных, имеющих тенденцию сохранять постоянные темпы прироста;
3. Логистическая:
 (272)
(272)
4. Гомперца
![]() (273), где
(273), где
Две последние модели задают кривые тренда S-образной формы. Они соответствуют процессам с постепенно возрастающими темпами роста в начальной стадии и постепенно затухающимитемпами роста в конце. Необходимость подобных моделей обусловлена невозможностью многих экономических процессов продолжительное время развиваться с постоянными темпами роста или по полиномиальным моделям, в связи с их довольно быстрым ростом (или уменьшением).
При прогнозировании тренд используют в первую очередь для долговременных прогнозов. Точность краткосрочных прогнозов, основанных только на подобранной кривой тренда, как правило, недостаточна.
Для оценки и удаления трендов из временных рядов чаще всего используется метод наименьших квадратов. Этот метод достаточно подробно рассматривался во втором разделе пособия в задачах линейного регрессионного анализа. Значения временного ряда рассматриваюткак отклик (зависимую переменную), а время t – какфактор, влияющий на отклик (независимую переменную).
Для временных рядов характерна взаимная зависимость его членов (по крайней мере, не далеко отстоящих по времени) и это является существенным отличием от обычного регрессионного анализа, для которого все наблюдения предполагаются независимыми. Тем не менее, оценки тренда и в этих условиях обычно оказываются разумными, если выбрана адекватная модель тренда и если среди наблюдений нет больших выбросов. Упомянутые выше нарушения ограничений регрессионного анализа сказываются не столько на значениях оценок, сколько наих статистических свойствах. Так, при наличии заметной зависимости между членами временного ряда оценки дисперсии, основанные на остаточнойсумме квадратов, дают неправильные результаты. Неправильными оказываются и доверительные интервалы для коэффициентов модели, и т.д. В лучшем случае их можно рассматривать как очень приближенные.
